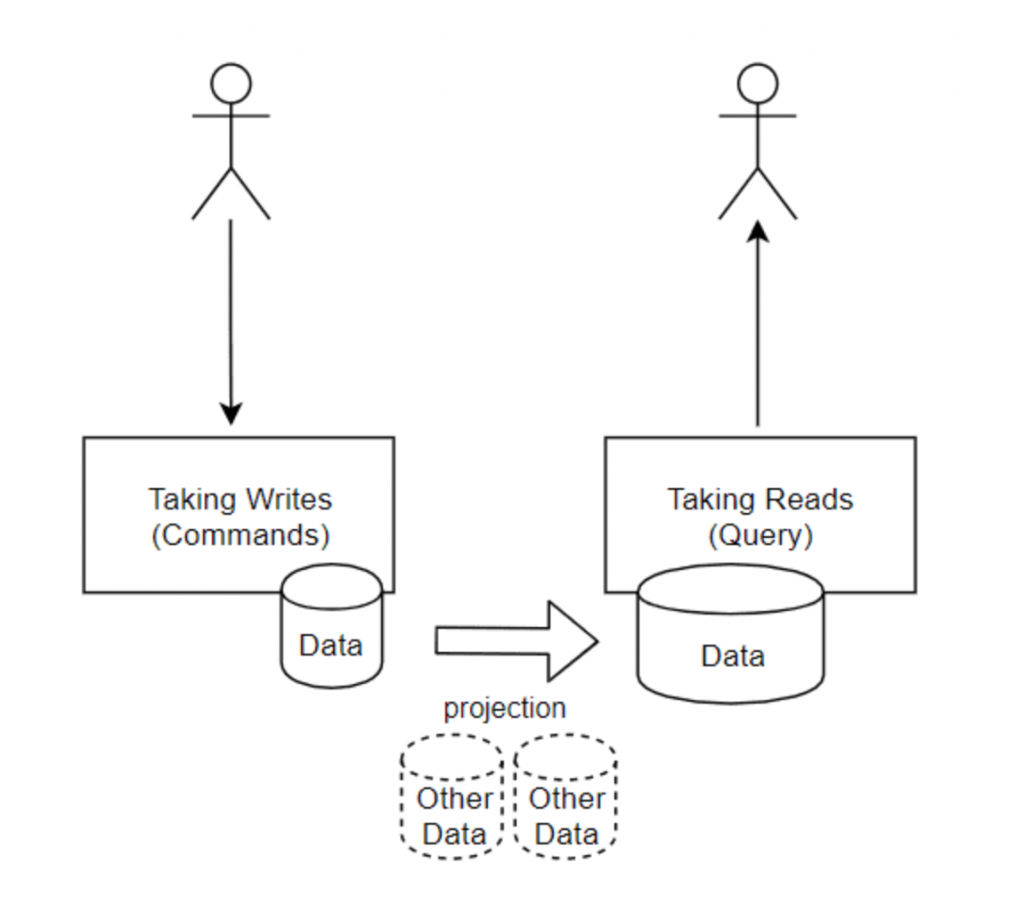
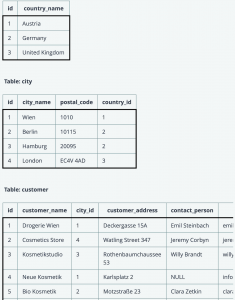
Database
What are the ACID properties in DBMS?
A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
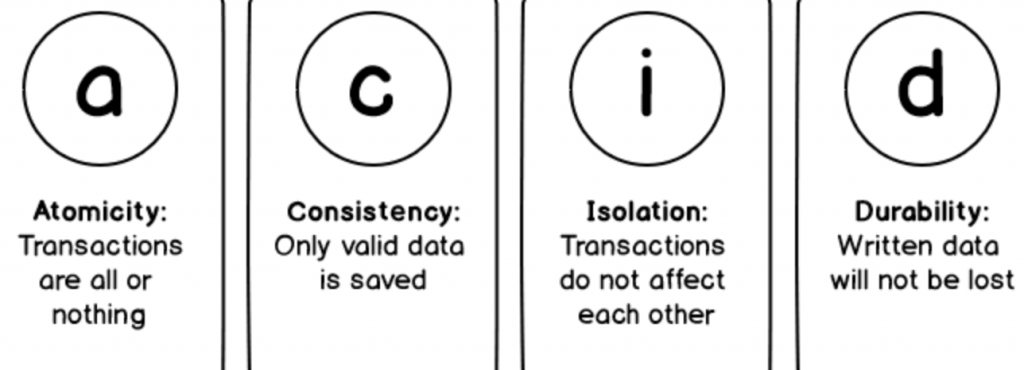
- Atomicity means that either rollback or commit the complete transaction.
- Consistency is handled by MySQL’s logging mechanisms, which record all changes happening to your database and help us to ensure that no in-consistency will occur.
- Isolation provides several low level locking which avoids (if properly handled) any other process to acquire lock on resource which is already in use by other process.
- MySQL implements durability by maintaining a binary transaction log file that tracks changes to the system during the course of a transaction. In the event of a hardware failure or abrupt system shutdown, recovering lost data is a relatively straightforward task by using the last backup in combination with the log when the system restarts. By default, InnoDB tables are 100 percent durable (in other words, all transactions committed to the system before the crash are liable to be rolled back during the recovery process), while MyISAM tables offer partial durability.
What is transaction?
A transaction is a logical unit of work that contains one or more SQL statements. Transactions are atomic units of work that can be committed or rolled back. When a transaction makes multiple changes to the database, either all the changes succeed when the transaction is committed, or all the changes are undone when the transaction is rolled back.
When should you use transactions in my queries?
- Use a transaction when you have a series of writes that need to be performed atomically; that is, they should all succeed or none should.
- Needs the ability to rollback every change, if an error occurs or some other reason.
Transaction best practices
Using the SQL Server transaction helps maintaining the database integrity and consistency. On the other hand, a badly written transaction may affect the overall performance of your system by locking the database resources for long time. To overcome this issue, it is better to consider the following points when writing a transaction:
- Narrow the scope of the transaction
- Retrieve the data from the tables before opening the transaction if possible
- Access the least amount of data inside the transaction body
- Do not ask for user input inside the body of the transaction
- Use a suitable mode of transactions
- Use as suitable Isolation Level for the transaction
SQL
Difference between DELETE and TRUNCATE
DELETE is a DML(Data Manipulation Language) command and is used when we specify the row(tuple) that we want to remove or delete from the table or relation. The DELETE command can contain a WHERE clause. If WHERE clause is used with DELETE command then it remove or delete only those rows(tuple) that satisfy the condition otherwise by default it removes all the tuples(rows) from the table.
TRUNCATE is a DDL(Data Definition Language) command and is used to delete all the rows or tuples from a table. Unlike the DELETE command, TRUNCATE command does not contain a WHERE clause. In the TRUNCATE command, the transaction log for each deleted data page is recorded. Unlike the DELETE command, the TRUNCATE command is fast. Like DELETE, we can rollback the data even after using the TRUNCATE command.
What is Pattern Matching in SQL?
- Using the % wildcard to perform a simple search
The % wildcard matches zero or more characters of any type and can be used to define wildcards both before and after the pattern. Search a student in your database with first name beginning with the letter K:- SELECT * FROM students WHERE first_name LIKE ‘K%’
- Omitting the patterns using the NOT keyword
Use the NOT keyword to select records that don’t match the pattern. This query returns all students whose first name does not begin with K.- SELECT * FROM students WHERE first_name NOT LIKE ‘K%’
- Matching a pattern anywhere using the % wildcard twice
Search for a student in the database where he/she has a K in his/her first name.- SELECT * FROM students WHERE first_name LIKE ‘%Q%’
- Using the _ wildcard to match pattern at a specific position
The _ wildcard matches exactly one character of any type. It can be used in conjunction with % wildcard. This query fetches all students with letter K at the third position in their first name.- SELECT * FROM students WHERE first_name LIKE ‘__K%’
- Matching patterns for specific length
The _ wildcard plays an important role as a limitation when it matches exactly one character. It limits the length and position of the matched results. For example –- SELECT * /* Matches first names with three or more letters */ FROM students WHERE first_name LIKE ‘___%’ SELECT * /* Matches first names with exactly four characters */ FROM students WHERE first_name LIKE ‘____’
How to create empty tables with the same structure as another table?
SELECT * INTO Students_copy FROM Students WHERE 1 = 2;
What is Normalization?
Normalization represents the way of organizing structured data in the database efficiently. It includes creation of tables, establishing relationships between them, and defining rules for those relationships. Inconsistency and redundancy can be kept in check based on these rules, hence, adding flexibility to the database.
What is Denormalization?
Denormalization is the inverse process of normalization, where the normalized schema is converted into a schema which has redundant information. The performance is improved by using redundancy and keeping the redundant data consistent. The reason for performing denormalization is the overheads produced in query processor by an over-normalized structure.
SQL Injection
SQL injection is a code injection technique that might destroy your database.
SQL Injection Based on 1=1 is Always True and Based on “”=”” is Always True
How to prevent SQL injection?
- Validate User Inputs and Sanitize Data
- Use Prepared Statements And Parameterization
HTML
Do your best to describe the process from the time you type in a website’s URL to it finishing loading on your screen? How is an HTML page rendered? What elements are created in what order?
Step 1 >> Get the ip address of the URL.
System checks the browser cache. Browser caches the DNS data for some time.
=> OS cache=> DNS cache maintained by the router => next level where DNS cache of your ISP => DNS query to search for the required DNS data.
Step 2>> Once the browser gets the IP address it opens TCP connection and sends HTTP request to the web server.
Step 3>> The web server will handle the request [it happens in multiple steps] and send the HTTP response to the client/browser.
Step 4>> The browser parse the HTML document and render it.
Rendering steps:
- Start downloading external files (JavaScript, CSS, images) as they’re encountered in the HTML
- Parse external files once they are downloaded (or if they are inline and don’t require downloading)
- if the files are scripts, then run them in the order they appear in the HTML
- if they try to access the DOM right now, they will throw an error
- while they run, they will prevent any other rendering, which is why some scripts are put at the bottom of the body
- for CSS files, save the style rules in order they appear in the HTML
- if they’re images then display them
- if the loading fails, then proceed without this file
- End HTML Parsing
- Create the DOM – including all the styles we have so far
- Execute the DOMContentLoaded event when the DOM is fully constructed and scripts are loaded and run happens even if all other external files (images, css) are not done downloading (from step 4) in the Chrome F12 developer tools this is represented by a blue line on the Network view will start running anything you’ve added to this event, e.g. window.addEventListener(“DOMContentLoaded”, doStuff, true);
- Start painting the document to the display window (with any styles that have already loaded)
- Execute the window.onload event when all external files have loaded in the Chrome F12 developer tools this is represented by a red line on the Network view this will start running the jQuery ready function $(document).ready(function(){ … }); will start running any code you’ve added to this event, e.g. window.addEventListener(“load”, doStuff, true);
- Re-paint the document, including any new images and styles
CSS
Can you describe specificity in CSS?
- Inline styles – An inline style is attached directly to the element to be styled. Example: <h1 style=”color: #ffffff;”>.
- IDs – An ID is a unique identifier for the page elements, such as #navbar.
- Classes, attributes and pseudo-classes – This category includes .classes, [attributes] and pseudo-classes such as :hover, :focus etc.
- Elements and pseudo-elements – This category includes element names and pseudo-elements, such as h1, div, :before and :after.
What are the values that you can position an element?
static, relative, absolute, fixed, sticky
Javascript
Can you explain closure in JS?
Closure means that an inner function always has access to the vars and parameters of its outer function, even after the outer function has returned. Closures keep access to the variables they can be used to save state. And things that save state look a whole lot like objects
Difference between const, let, and var
var declarations are globally scoped or function scoped while let and const are block scoped. var variables can be updated and re-declared within its scope; let variables can be updated but not re-declared; const variables can neither be updated nor re-declared. They are all hoisted to the top of their scope
What are the areas of scope in JS?
- Global scope
- Local scope / function scope
- Block scope – introduced in ES6 that limits a variables scope to a given parenthesis block
What’s the difference between bind, apply and call?
The call, bind and apply methods can be used to set the this keyword independent of how a function is called. The bind method creates a copy of the function and sets the this keyword, while the call and apply methods sets the this keyword and calls the function immediately.
call requires the arguments to be passed in one-by-one, and apply takes the arguments as an array.
PHP
What is the difference between single-quoted and double-quoted strings in PHP?
- Single quoted strings will display things almost completely “as is.” Variables and most escape sequences will not be interpreted. The exception is that to display a literal single quote, you can escape it with a back slash
\', and to display a back slash, you can escape it with another backslash\\(So yes, even single quoted strings are parsed). - Double quote strings will display a host of escaped characters (including some regexes), and variables in the strings will be evaluated. An important point here is that you can use curly braces to isolate the name of the variable you want evaluated. For example let’s say you have the variable
$typeand you want toecho "The $types are". That will look for the variable$types. To get around this useecho "The {$type}s are"You can put the left brace before or after the dollar sign. Take a look at string parsing to see how to use array variables and such.
How to check whether a variable is null in PHP?
Answer: Use the PHP is_null() function or === NULL
Concept
What is ORM?
ORM stands for Object-Relational Mapping (ORM) is a programming technique for converting data between relational databases and object oriented programming languages such as PHP, Java, C#, etc.
An ORM system has the following advantages:
- Let’s business code access objects rather than DB tables.
- Hides details of SQL queries from OO logic.
- No need to deal with the database implementation.
- Entities based on business concepts rather than database structure.
- Transaction management and automatic key generation.
- Fast development of application.
What is Dependency Injection?
Dependency Injection (DI) is a design pattern used to implement IoC. It allows the creation of dependent objects outside of a class and provides those objects to a class through different ways. Using DI, we move the creation and binding of the dependent objects outside of the class that depends on them.
What is Inversion of Control?
Inversion of control is a broad term but for a software developer it’s most commonly described as a pattern used for decoupling components and layers in the system. For example, creates a dependency between the TextEditor and the SpellChecker.
public class TextEditor {
private SpellChecker checker;
public TextEditor(SpellChecker checker) {
this.checker = checker;
}
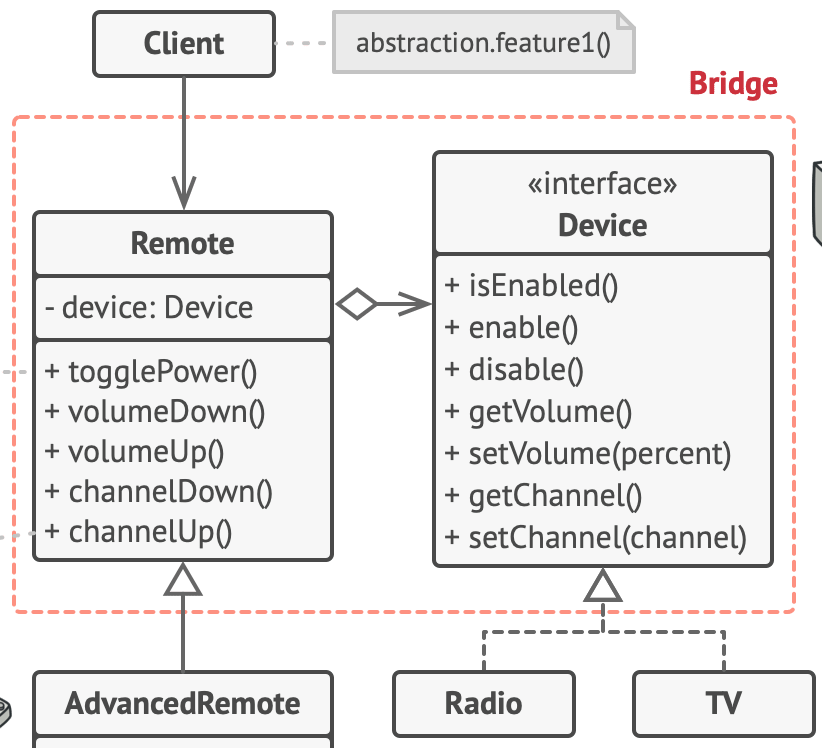
}What is Bridge pattern?
Bridge pattern is used when we need to decouple an abstraction from its implementation so that the two can vary independently. This type of design pattern comes under structural pattern as this pattern decouples implementation class and abstract class by providing a bridge structure between them.
The bridge pattern is useful when both the class and what it does vary often. The class itself can be thought of as the abstraction and what the class can do as the implementation. The bridge pattern can also be thought of as two layers of abstraction.
Docker
Explain a use case for Docker
- Docker is a low overhead way to run virtual machines on your local box or in the cloud. They’re not strictly distinct machines, they don’t need to boot an OS.
- Docker can encapsulate legacy applications, allowing you to deploy them to servers that might not be easy to setup with older packages and software version.
- Docker can be used to build test boxes, during your deploy process to facilitate continuous integration(CI) testing.
- Docker can be used to provision boxes in the cloud, and with swarm you can orchestrate clusters too
API
Explain the main difference between REST and GraphQL
The main and most important difference between REST and GraphQL is that GraphQL is not dealing with dedicated resources, instead everything is regarded as a graph and therefore is connected and can be queried to app exact needs.
If you were to implement an API endpoint for checking if a resource exists, what path and method would you use?
RESTful path should only contain nouns–the method used on the endpoint should determine the action.
- POST /users create a user model
- PUT /users/{id|slug} replace a user model
- PATCH /users/{id|slug} update part of a user model
- DELETE /users/{id|slug} delete a user model
- GET /users/{id|slug} retrieve a user model
The commonly accepted way to determine if a resource exists, using the above “user” resource as an example, then:
- HEAD /users/{id|slug}
This request will use the least amount of bandwidth as it will return no data, simply just a 200 or 404 HTTP status.
A common issue when integrating third-party services within your own API requests is having to wait for the response, and as such, forcing the user to have to wait for a longer time. How would you do to avoid this?
The most effective way to solve this problem is to use queues. When a request is made to our API, a separate job is then created and added to a queue. This job will then be executed independently to the requested endpoint, thus allowing the server to respond without delay.
Message queue providers: Beanstalkd, RabbitMQ
How would you prevent a bot from scraping your publicly accessible API?
Technically, it is not possible to completely prevent data scraping. However, there is an effective solution that will deter most bots: rate limiting (throttling).
Throttling will prevent a certain device from making a defined number of requests within a defined time. Upon exceeding the defined number of requests, a 429 Too Many Attempts HTTP error should be thrown.
Note: It is important to track the device with more than just an IP address as this is not unique to the device and can result in an entire network losing access to an API.
Other less-than-ideal answers include:
- Blocking requests based on the user agent string (easy to find a way around)
- Generating temporary “session” access tokens for visitors at the front end.(this isn’t secure: storing a secret on the front end can be reverse-engineered, thus allowing anyone to generate access tokens)
If a user attempts to create a resource that already exists, what HTTP status code would you return?
Use a 409 conflict HTTP status code / 400 bad request
Node.js
What is Event Loop?
Node.js is a single threaded application but it support concurrency via concept of event and callbacks. As every API of Node js are asynchronous and being a single thread, it uses async function calls to maintain the concurrency. Node uses observer pattern. Node thread keeps an event loop and whenever any task get completed, it fires the corresponding event which signals the event listener function to get executed.
SEO
List some key things to consider when coding with SEO in mind
In order to build a site optimized for organic search engine rankings, it is important to implement certain standards throughout the code. These include:
- Using the correct HTML tags for content hierachy i.e. <h1>/<h2>/<h3> and p
- Use alt tag on images
- Use vanity/friendly URLs (human readable)
- Add XML sitemap
- Add robots.txt file
- Integrate Google analytics
- Avoid broken links
- Avoid Javascript errors
- Avoid W3C markup validation errors
- Minify your assets
- Enable and force SSL
- Include a meta description on each page
- Specify relevant meta tags
- Specify a favicon
- Specify unique title for each page without exceeding 70 characters
- Ensure there is enough content with enough relevant keywords
- Leverage browser caching
List some ways you could optimize a website to be as efficient and scalable as possible.
- Ensure no validation errors with W3C
- Minified all your assets and all code
- Place all assets on CDN
- Reduce cookie size
- Avoid inline Javascript and CSS
- Leverage browser caching
- Prefer async resources
- Reduce DNS lookups
- Avoid URL redirects
- Avoid CSS @import
- Serve scaled images, SVG
- Avoid unnecessary images; where possible use CSS
- Enable HTTP keep-alive
- Minimize request size, avoid bad requests and 404s
- Make fewer HTTP requests, load as few external resource as possible
To be continue….