Source from: https://medium.com/@sderosiaux/cqrs-what-why-how-945543482313
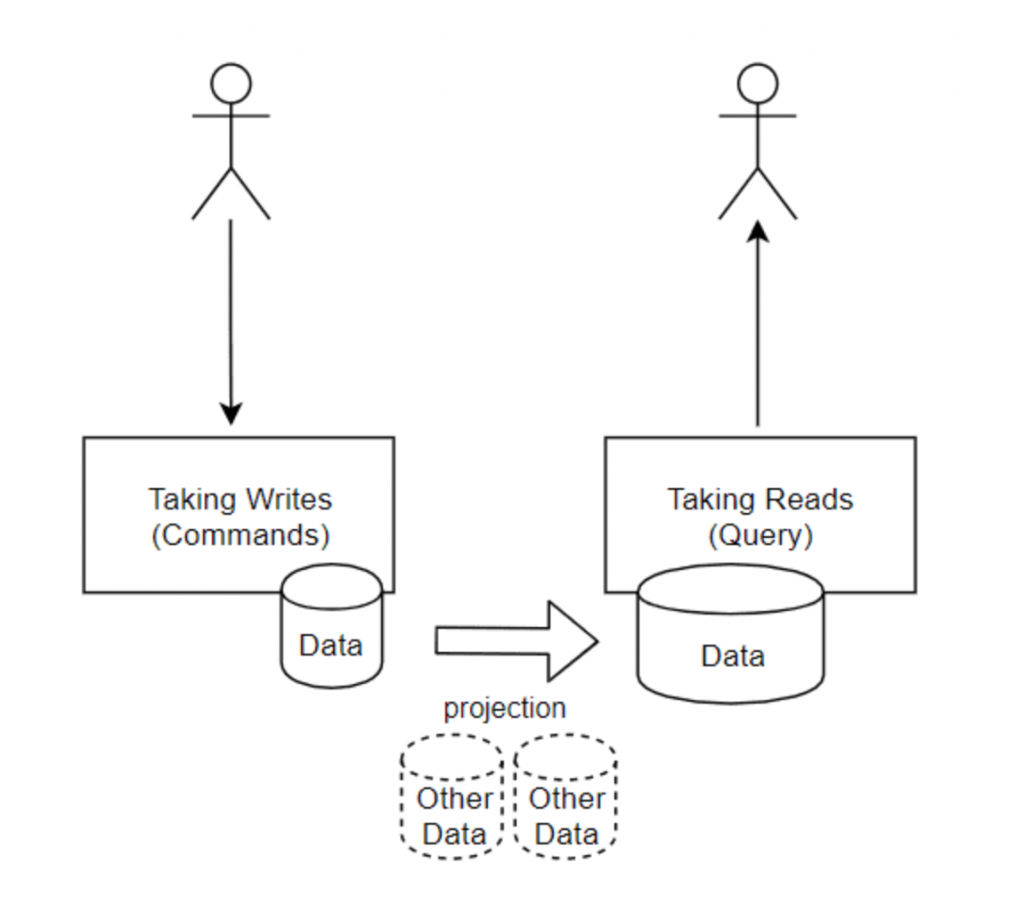
One Write Model, N Read Models
The idea of CQRS is to enable an application (in the large sense) to work with different models:
- One internal model it writes with: the write model, altered by Commands (more on this later)
- One or several read models it and other applications read from (we can’t let others read the write model)
This pattern trade control over scalability and flexibility.
Advantages:
- We can scale the read and write databases independently of each other
- The write database can be normalized to 3rd Normal Form to make writes efficient
- The read databases can be denormalized the data to suit specific queries and no need to perform complex operations like JOIN tables to return the required data.
- Managing security and permissions is easy
- It makes queries simple
- It forces us to change the way we think, UI sends a command to the write model and not a data model object
- We can use a relational database for the write side and use NoSQL database for the read side. Scaling a NoSQL database is relatively easy.
Disadvantages:
- It makes the whole system complex
- Data can be stale
- Handling eventually consistent data is a monster of its own.
Points to consider before implementation
- This is not a system-wide or high-level pattern. It should be applied only in a bounded context where it makes sense.
- The data will be eventually consistent
- It works well with event sourcing pattern
- It is useful in systems where multiple systems/actors perform parallel actions on the same data.
- It shouldn’t be used for applications which are simple CRUD based.
- The write model is always the source of truth. So we could query the write model and return data as the result of command execution.
- It is not simple to handle eventual-consistent data.